swmmio¶
v0.4.9 (2022/02/22)

swmmio is a set of python tools aiming to provide a means for version control and visualizing results from the EPA Stormwater Management Model (SWMM). Command line tools are also provided for running models individually and in parallel via Python’s multiprocessing module. These tools are being developed specifically for the application of flood risk management, though most functionality is applicable to SWMM modeling in general.
Prerequisites¶
swmmio functions primarily by interfacing with .inp and .rpt (input and report) files produced by SWMM. Functions within the run_models module rely on a SWMM5 engine which can be downloaded here.
Installation:¶
Before installation, it’s recommended to first activate a virtualenv to not crowd your system’s package library. If you don’t use any of the dependencies listed above, this step is less important. SWMMIO can be installed via pip in your command line:
pip install swmmio
Basic Usage¶
The swmmio.Model() class provides the basic endpoint for interfacing with SWMM models. To get started, save a SWMM5 model (.inp) in a directory with its report file (.rpt). A few examples:
import swmmio
#instantiate a swmmio model object
mymodel = swmmio.Model('/path/to/directory with swmm files')
# Pandas dataframe with most useful data related to model nodes, conduits, and subcatchments
nodes = mymodel.nodes.dataframe
links = mymodel.links.dataframe
subs = mymodel.subcatchments.dataframe
#enjoy all the Pandas functions
nodes.head()
| InvertElev | MaxDepth | SurchargeDepth | PondedArea | Type | AvgDepth | MaxNodeDepth | MaxHGL | MaxDay_depth | MaxHr_depth | HoursFlooded | MaxQ | MaxDay_flood | MaxHr_flood | TotalFloodVol | MaximumPondDepth | X | Y | coords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | |||||||||||||||||||
| S42A_10.N_4 | 13.506673 | 6.326977 | 5.0 | 110.0 | JUNCTION | 0.69 | 6.33 | 19.83 | 0 | 12:01 | 0.01 | 0.20 | 0.0 | 11:52 | 0.000 | 6.33 | 2689107.0 | 227816.000 | [(2689107.0, 227816.0)] |
| D70_ShunkStreet_Trunk_43 | 8.508413 | 2.493647 | 5.0 | 744.0 | JUNCTION | 0.04 | 0.23 | 8.74 | 0 | 12:14 | NaN | NaN | NaN | NaN | NaN | NaN | 2691329.5 | 223675.813 | [(2691329.5, 223675.813)] |
| TD61_1_2_90 | 5.150000 | 15.398008 | 0.0 | 0.0 | JUNCTION | 0.68 | 15.40 | 20.55 | 0 | 11:55 | 0.01 | 19.17 | 0.0 | 11:56 | 0.000 | 15.40 | 2698463.5 | 230905.720 | [(2698463.5, 230905.72)] |
| D66_36.D.7.C.1_19 | 19.320000 | 3.335760 | 5.0 | 6028.0 | JUNCTION | 0.57 | 3.38 | 22.70 | 0 | 12:00 | 0.49 | 6.45 | 0.0 | 11:51 | 0.008 | 3.38 | 2691999.0 | 230309.563 | [(2691999.0, 230309.563)] |
#write to a csv
nodes.to_csv('/path/mynodes.csv')
#calculate average and weighted average impervious
avg_imperviousness = subs.PercImperv.mean()
weighted_avg_imp = (subs.Area * subs.PercImperv).sum() / len(subs)
Nodes and Links Objects¶
Specific sections of data from the inp and rpt can be extracted with Nodes and Links objects.
Although these are the same object-type of the swmmio.Model.nodes and swmmio.Model.links,
accessing them directly allows for custom control over what sections of data are retrieved.
from swmmio import Model, Nodes
m = Model("coolest-model.inp")
# pass custom init arguments into the Nodes object instead of using default settings referenced by m.nodes()
nodes = Nodes(
model=m,
inp_sections=['junctions', 'storages', 'outfalls'],
rpt_sections=['Node Depth Summary', 'Node Inflow Summary'],
columns=[ 'InvertElev', 'MaxDepth', 'InitDepth', 'SurchargeDepth', 'MaxTotalInflow', 'coords']
)
# access data
nodes.dataframe
Generating Graphics¶
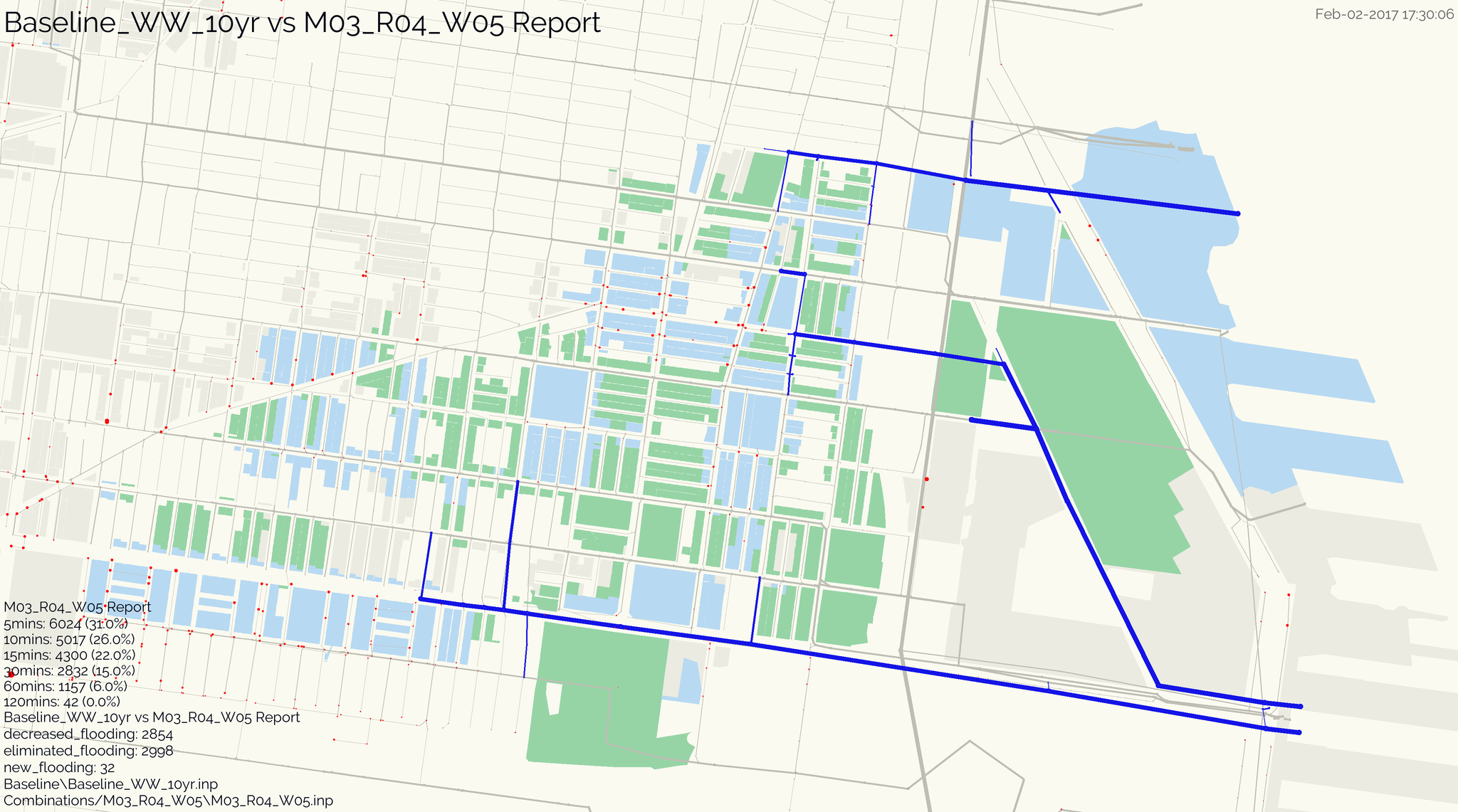
Create an image (.png) visualization of the model. By default, pipe stress and node flood duration is visualized if your model includes output data (a .rpt file should accompany the .inp).
from swmmio.graphics import swmm_graphics as sg
sg.draw_model(mymodel)
Use pandas to calculate some interesting stats, and generate a image to highlight what’s interesting or important for your project:
#isolate nodes that have flooded for more than 30 minutes
flooded_series = nodes.loc[nodes.HoursFlooded>0.5, 'TotalFloodVol']
flood_vol = sum(flooded_series) #total flood volume (million gallons)
flooded_count = len(flooded_series) #count of flooded nodes
#highlight these nodes in a graphic
nodes['draw_color'] = '#787882' #grey, default node color
nodes.loc[nodes.HoursFlooded>0.5, 'draw_color'] = '#751167' #purple, flooded nodes
#set the radius of flooded nodes as a function of HoursFlooded
nodes.loc[nodes.HoursFlooded>1, 'draw_size'] = nodes.loc[nodes.HoursFlooded>1, 'HoursFlooded'] * 12
#make the conduits grey, sized as function of their geometry
conds['draw_color'] = '#787882'
conds['draw_size'] = conds.Geom1
#add an informative annotation, and draw:
annotation = 'Flooded Volume: {}MG\nFlooded Nodes:{}'.format(round(flood_vol), flooded_count)
sg.draw_model(mymodel, annotation=annotation, file_path='flooded_anno_example.png')

Building Variations of Models¶
Starting with a base SWMM model, other models can be created by inserting altered data into a new inp file. Useful for sensitivity analysis or varying boundary conditions, models can be created using a fairly simple loop, leveraging the modify_model package.
For example, climate change impacts can be investigated by creating a set of models with varying outfall Fixed Stage elevations:
import os
import swmmio
#initialize a baseline model object
baseline = swmmio.Model(r'path\to\baseline.inp')
rise = 0.0 #set the starting sea level rise condition
#create models up to 5ft of sea level rise.
while rise <= 5:
#create a dataframe of the model's outfalls
outfalls = baseline.inp.outfalls
#create the Pandas logic to access the StageOrTimeseries column of FIXED outfalls
slice_condition = outfalls.OutfallType == 'FIXED', 'StageOrTimeseries'
#add the current rise to the outfalls' stage elevation
outfalls.loc[slice_condition] = pd.to_numeric(outfalls.loc[slice_condition]) + rise
baseline.inp.outfalls = outfalls
#copy the base model into a new directory
newdir = os.path.join(baseline.inp.dir, str(rise))
os.mkdir(newdir)
newfilepath = os.path.join(newdir, baseline.inp.name + "_" + str(rise) + '_SLR.inp')
#Overwrite the OUTFALLS section of the new model with the adjusted data
baseline.inp.save(newfilepath)
#increase sea level rise for the next loop
rise += 0.25
Access Model Network¶
The swmmio.Model class returns a Networkx MultiDiGraph representation of the model via that network parameter:
#access the model as a Networkx MutliDiGraph
G = model.network
#iterate through links
for u, v, key, data in model.network.edges(data=True, keys=True):
print (key, data['Geom1'])
# do stuff with the network
Running Models¶
Using the command line tool, individual SWMM5 models can be run by invoking the swmmio module in your shell as such:
$ python -m swmmio --run path/to/mymodel.inp
If you have many models to run and would like to take advantage of your machine’s cores, you can start a pool of simulations with the --start_pool (or -sp) command. After pointing -sp to one or more directories, swmmio will search for SWMM .inp files and add all them to a multiprocessing pool. By default, -sp leaves 4 of your machine’s cores unused. This can be changed via the -cores_left argument.
$ #run all models in models in directories Model_Dir1 Model_Dir2
$ python -m swmmio -sp Model_Dir1 Model_Dir2
$ #leave 1 core unused
$ python -m swmmio -sp Model_Dir1 Model_Dir2 -cores_left=1
Warning
Using all cores for simultaneous model runs can put your machine's CPU usage at 100% for extended periods of time. This probably puts stress on your hardware. Use at your own risk.
Flood Model Options Generation¶
swmmio can take a set of independent storm flood relief (SFR) alternatives and combine them into every combination of potential infrastructure changes. This lays the ground work for identifying the most-efficient implementation sequence and investment level.
Consider the simplified situaiton where a city is interested in solving a flooding issue by installing new relief sewers along Street A and/or Street B. Further, the city wants to decide whether they should be 1 or 2 blocks long. Engineers then decide to build SWMM models for 4 potential relief sewer options:
A1 -> One block of relief sewer on Street A
A2 -> Two blocks of relief sewer on Street A
B1 -> One block of relief sewer on Street B
B2 -> Two blocks of relief sewer on Street B
To be comprehensive, implementation scenarios should be modeled for combinations of these options; it may be more cost-effective, for example, to build relief sewers on one block of Street A and Street B in combination, rather than two blocks on either street independently.
swmmio achieves this within the version_control module. The create_combinations() function builds models for every logical combinations of the segmented flood mitigation models. In the example above, models for the following scenarios will be created:
A1 with B1
A1 with B2
A2 with B1
A2 with B2
For the create_combinations() function to work, the model directory needs to be set up as follows:
├───Baseline
baseline.inp
├───Combinations
└───Segments
├───A
│ ├───A1
│ │ A1.inp
│ └───A2
│ A2.inp
└───B
├───B1
│ B1.inp
└───B2
B2.inp
The new models will be built and saved within the Combinations directory. create_combinations() needs to know where these directories are and optionally takes version_id and comments data:
#load the version_control module
from swmmio.version_control import version_control as vc
#organize the folder structure
baseline_dir = r'path/to/Baseline/'
segments_dir = r'path/to/Segments/'
target_dir = r'path/to/Combinations/'
#generate flood mitigation options
vc.create_combinations(
baseline_dir,
segments_dir,
target_dir,
version_id='initial',
comments='example flood model generation comments')
The new models will be saved in subdirectories within the target_dir. New models (and their containing directory) will be named based on a concatenation of their parent models’ names. It is recommended to keep parent model names as concise as possible such that child model names are manageable. After running create_combinations(), your project directory will look like this:
├───Baseline
├───Combinations
│ ├───A1_B1
│ ├───A1_B2
│ ├───A2_B1
│ └───A2_B2
└───Segments
├───A
│ ├───A1
│ └───A2
└───B
├───B1
└───B2
SWMM Model Version Control¶
To add more segments to the model space, create a new segment directory and rerun the create_combinations() function. Optionally include a comment summarizing how the model space is changing:
vc.create_combinations(
baseline_dir,
alternatives_dir,
target_dir,
version_id='addA3',
comments='added model A3 to the scope')
The create_combinations() function can also be used to in the same way to propogate a change in an existing segment (parent) model to all of the children. Version information for each model is stored within a subdirectory called vc within each model directory. Each time a model is modified from the create_combinations() function, a new “BuildInstructions” file is generated summarizing the changes. BuildInstructions files outline how to recreate the model with respect to the baseline model.
TO BE CONTINUED…